Kitchen And Dining,Multifunction Electric Health Pot,Stainless Steel Electric Health Pot,Electric Heating Soup Kettle GUANGDONG DEERMA TECHNOLOGY CO., LTD. , https://www.nbguangdongdeerma.com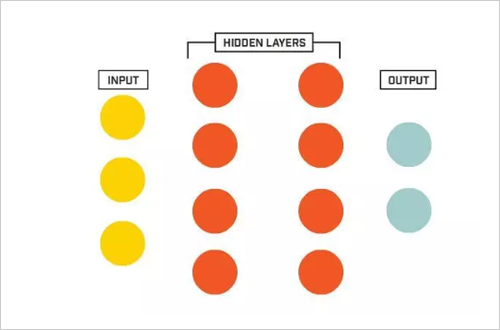

In 2016, AlphaGo defeated South Korea's Li Shishi. In media reports, he repeatedly mentioned the concept of “deep learningâ€. The new version of AlphaGoZero, more fully use the deep learning method, no longer start training from the previous chess record of the human player, but rely on their own learning algorithm to learn to play chess through self-game. After a period of self-learning, it defeated the AlphaGo version that had defeated Li Shishi and had won Ke Jie.
It can be seen that the machine does begin to have some kind of learning ability. What it gets in training is not just rules and object information, but also the possible conditions for the object to appear. In other words, it has been able to begin to “feel†and capture possibilities, not just ready-made. This kind of learning is a quasi-occurrence process of non-linear, probabilistic, feedback-adjusted and layer-by-layer deepening and composition. This is a process of acquisition with some real time history.
What is deep learning?
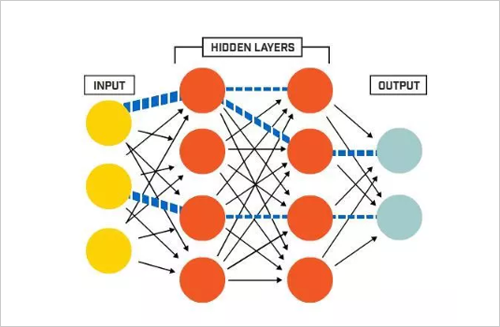
Deep learning is a form of machine learning that employs a neural network with many "depth" layers between the input node and the output node. By training the network based on a large data set, the model created can be used to make accurate predictions based on input data. In a neural network for deep learning, the output of each layer is fed forward to the input of the next layer. The model is iteratively optimized by changing the weighting of the connections between the layers. At each cycle, feedback on model prediction accuracy will be used to guide connection weighted changes.
A neural network with a "depth" hidden layer between input and output:
Relative input weighted changes:
Artificial intelligence, machine learning and deep learning
As shown above, the earliest artificial intelligence is located at the outermost side of the concentric circle; secondly, the machine learning that is subsequently developed, located in the middle; and finally, the deep learning that promotes the rapid development of artificial intelligence, located at the innermost side.
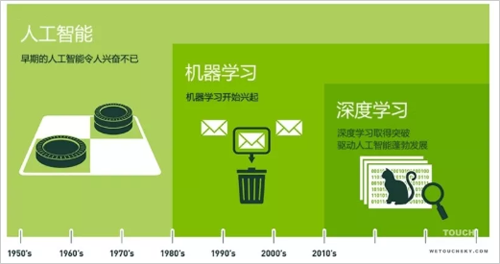
Since the artificial intelligence fever of the 1950s, machine learning and deep learning based on the concept of artificial intelligence have set off an unprecedented wave of new waves.
In 1956, several computer scientists first proposed the concept of "artificial intelligence" at the Dartmouth meeting. Since then, artificial intelligence has been lingering in people's minds and is gaining momentum in research laboratories. In the following decades, artificial intelligence has been reversed at the poles. Some people call it the key to unlocking the brilliant future of human civilization, and others have thrown it into the technical garbage heap as a madman of technology lunatics. In fact, before 2012, these two views have been comparable.
In the past few years, especially since 2015, artificial intelligence has grown by leaps and bounds. This is mainly due to the widespread use of graphics processing units (GPUs), making parallel computing faster, cheaper, and more efficient. Of course, the combination of infinitely expanded storage capacity and sudden bursts of data torrents (big data) has also led to a massive explosion of image data, text data, transaction data, and mapping data.
1, machine learning - the way to achieve artificial intelligence
The most basic approach to machine learning is to use algorithms to parse data, learn from it, and then make decisions and predictions about events in the real world. Unlike traditional software programs that solve specific tasks and hard code, machine learning uses a large amount of data to "train" and learn how to accomplish tasks from data through various algorithms.
Machine learning comes directly from the early days of artificial intelligence. Traditional algorithms include decision tree learning, derivation logic planning, clustering, reinforcement learning, and Bayesian networks. As we all know, we have not yet achieved strong artificial intelligence. Early machine learning methods could not even achieve weak artificial intelligence.
The most successful application area for machine learning is computer vision, although it still requires a lot of manual coding to get the job done. People need to manually write the classifier and edge detection filter so that the program can recognize where the object starts and where it ends; write the shape detection program to determine whether the object has eight edges; write the classifier to recognize the letter "ST-OP ". Using these hand-written classifiers, one can finally develop an algorithm to perceive the image and determine if the image is a stop sign.
2, deep learning - technology to achieve machine learning
Artificial neural networks are an important algorithm in early machine learning. The principle of neural networks is inspired by the physiological structures of our brains, which are intertwined with neurons. But unlike any neuron in a brain that can be connected within a certain distance, the artificial neural network has discrete layers, connections, and directions of data propagation.
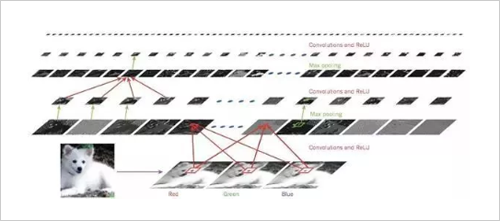
For example, we can split an image into image blocks and input them to the first layer of the neural network. Each neuron in the first layer passes the data to the second layer. The second layer of neurons also performs a similar job, passing the data to the third layer, and so on, until the last layer, and then generating the result.
Each neuron assigns a weight to its input, and the correctness of this weight is directly related to the task it performs. The final output is determined by the sum of these weights.
Let's stop the (Stop) sign as an example. Break all elements of a stop sign image and then "check" with neurons: the shape of the octagon, the red color of the train, the prominent letters, the typical size of the traffic sign, and the stationary motion Features and more. The task of the neural network is to give a conclusion as to whether it is a stop sign. The neural network gives a well-thought-out guess based on the weight of ownership - the "probability vector."
In this example, the system might give the result: 86% might be a stop sign; 7% might be a speed limit sign; 5% might be a kite hanging on a tree and so on. The network structure then tells the neural network whether its conclusions are correct.
In fact, in the early days of artificial intelligence, neural networks existed, but the contribution of neural networks to "smart" was minimal. The main problem is that even the most basic neural networks require a lot of computation. The computational requirements of neural network algorithms are difficult to meet.
Now, image recognition through deep learning training can even be better than humans in some scenarios: from recognizing cats, to identifying early components of cancer in the blood, to identifying tumors in MRI. Google's AlphaGo first learned how to play Go and then played chess with it. The way it trains its own neural network is to constantly play chess with itself, repeat it underground, and never stop.
Deep learning related technology
Deep learning allows computational models with multiple processing layers to learn representations of data with multiple levels of abstraction. These methods have brought significant improvements in many areas, including advanced speech recognition, visual object recognition, object detection, and many other areas. Deep learning can discover complex structures in big data. Deep convolutional networks have made a breakthrough in processing images, video, voice, and audio, while recursive networks have shown a shining side in processing sequence data, such as text and speech.
For decades, to build a pattern recognition system or machine learning system, you need a sophisticated engine and considerable expertise to design a feature extractor that converts raw data (such as the pixel values ​​of an image) into an appropriate internal feature. A representation or feature vector, a sub-learning system, usually a classifier that detects or classifies incoming samples. Feature Representation Learning is a set of methods that injects raw data into a machine and then automatically discovers the expressions that need to be detected and classified.
Deep learning is a feature learning method that transforms raw data into higher-level, more abstract expressions through simple but non-linear models. Very complex functions can also be learned with a combination of enough conversions.
1. Supervised learning
In machine learning, whether it is deep or not, the most common form is supervised learning. We want to build a system that categorizes an image that contains a house, a car, a person, or a pet. We first collect a large collection of images of houses, cars, people and pets, and mark each object with its category. During training, the machine takes a picture and produces an output, which is represented by a fraction in vector form, and each category has a vector like this. We hope that the required category has a high score in all categories, but this is unlikely to happen before training. The error (or distance) between the output score and the expected mode score can be obtained by calculating an objective function. The machine then modifies its internal tunable parameters to reduce this error. These adjustable parameters, often referred to as weights, are real numbers that define the machine's input and output capabilities.
In a typical deep learning system, there may be millions of samples and weights, and labeled samples to train the machine. In order to correctly adjust the weight vector, the learning algorithm calculates a gradient vector for each weight, indicating the amount by which the error will increase or decrease if the weight is increased by a small amount. The weight vector is then adjusted in the opposite direction of the gradient vector. Our objective function, the average of all training samples, can be thought of as a variable terrain in a high-dimensional space of weights. A negative gradient vector indicates that the direction of the fall is the fastest in the terrain, making it closer to the minimum, which is where the average output error is lowest.
2, convolutional neural network
The convolutional neural network is designed to process multidimensional array data, such as a color image with 3 color channels combined with 3 pixel-value 2-D images. Many data forms are such multidimensional arrays: 1D is used to indicate signals and sequences include language, 2D is used to represent images or sounds, and 3D is used to represent video or images with sound. Convolutional neural networks use four key ideas to take advantage of the properties of natural signals: local connections, weight sharing, pooling, and the use of multiple network layers.
A typical convolutional neural network structure consists of a series of processes. The first few stages are composed of a convolutional layer and a pooled layer. The units of the convolutional layer are organized in a feature map. In the feature map, each unit is connected to the previous one by a set of weights called filters. A local block of the feature map of the layer, which is then passed to a nonlinear function, such as ReLU. All cells in one feature map enjoy the same filter, and feature maps of different layers use different filters. The reasons for using this structure are twofold:
(1) In array data, such as image data, values ​​near a value are often highly correlated, and can form discriminative local features that are relatively easy to detect.
(2) The local statistical features of different locations are not relevant, that is to say, a certain feature appearing in one place may also appear elsewhere, so units in different locations can share weights and can detect the same sample. Mathematically, this filtering operation performed by a feature map is an offline convolution, and the convolutional neural network is so famous.
Many of the natural signals utilized by deep neural networks are hierarchically composed of attributes in which advanced features are achieved through a combination of low-level features. In an image, the combination of local edges forms a basic pattern that forms part of the object and then forms an object. This hierarchical structure also exists in speech data as well as text data, such as sounds, factors, syllables, words and sentences in documents in dian. When the position of the input data changes in the previous layer, the pooling operation makes these feature representations robust to these changes.
3, using deep convolution network for image understanding
Since the beginning of the 21st century, convolutional neural networks have been successfully used in various fields of detection, segmentation, object recognition, and images. These applications use a large amount of tagged data, such as traffic signal recognition, biometric segmentation, face detection, text, pedestrians, and the detection of human body parts in natural graphics. In recent years, a major successful application of convolutional neural networks has been face recognition.
Images can be tagged at the pixel level so that they can be used in technologies such as automatic dian answering robots, self-driving cars, and the like. Like Mobileye and NVIDIA, the convolutional neural network-based approach is being used in vision systems in automobiles. Other applications involve the understanding of natural language and speech recognition.
Today's convolutional neural network architecture has 10-20 layers of ReLU activation functions, millions of weights, and billions of connections. However, training such a large network took only a few weeks two years ago, and now the parallel advancement of hardware, software and algorithms has reduced the training time to hours.
Convolutional neural networks are easily implemented in chips or field-programmable gate arrays (FPGAs), and many companies are developing convolutional neural network chips to enable real-time vision systems in smartphones, cameras, robots, and autonomous vehicles. .
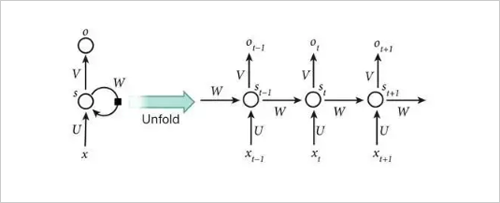
4. Recurrent neural network
When introducing backpropagation algorithms, the most exciting thing is to use recurrent neural network training. For tasks involving sequence input, such as speech and language, RNNs can be used to get better results. The RNNs process an input sequence element at a time while maintaining an implicit "state vector" containing the historical information of the elements of the past time sequence in the implicit unit of the network. If it is the output of different neurons in a deep multi-layer network, we will consider the output of such implicit units at different discrete time steps, which will give us a clearer idea of ​​how to use backpropagation to train RNNs.
RNNs are very powerful dynamic systems, but training them proves to be problematic because the gradient of backpropagation increases or decreases during each time interval, so over time it will cause a sharp increase or decrease to zero.
Due to the advanced architecture and training methods, RNNs were found to be able to predict the next word in the text or the next word in the sentence, and can be applied to more complex tasks. For example, after reading a word in an English sentence at a certain time, an English "encoder" network will be trained so that the final state vector of the implicit unit can well represent the meaning or thought to be expressed by the sentence. This "thought vector" can be used as a joint implicit state (or additional input) for joint training of a French "encoder" network, the output of which is the probability distribution of the French translation of the first word. If a particular first word is selected from the distribution as input to the encoding network, the probability distribution of the second word in the translated sentence will be output until the selection is stopped. In general, this process is a sequence of French vocabulary based on the probability distribution of English sentences. The performance of this simple machine translation method is comparable to that of advanced methods, and it also raises questions about whether a sentence needs to be manipulated as if it were to use internal rules. This is in line with the idea that day-to-day reasoning involves analogy with reasonable conclusions.
Major differences in machine learning and deep learning
Both deep learning and machine learning provide a way to train models and classify data. So what is the difference between the two?
Using standard machine learning methods, we need to manually select the relevant features of the image to train the machine learning model. The model then references these features as they are analyzed and categorized.
Through the deep learning workflow, relevant functions can be automatically extracted from the image. In addition, deep learning is an end-to-end learning, the network is given tasks such as raw data and classification, and can be done automatically.
Another key difference is the deep learning algorithm and data scaling, while the shallow learning data converges. Shallow learning refers to the way machine learning can reach platform level at a specific performance level as users add more examples and training data to the network.
If you need to make a choice between deep learning and machine learning, you need to know whether you have a high-performance GPU and a lot of tagged data. Machine learning is more advantageous than deep learning if users don't have high-performance GPUs and tagged data. This is because deep learning is often more complicated and may require thousands of images in order to obtain reliable results. A high-performance GPU can help users spend less time analyzing all the images in modeling.
If the user chooses machine learning, he or she can choose to train the model on a variety of different classifiers, and also know which functions can extract the best results. In addition, through machine learning, we have the flexibility to choose a combination of multiple methods, using different classifiers and functions to see which alignment is best for the data.
So, in general, deep learning is more computationally intensive, and machine learning techniques are generally easier to use.
Deep learning, the future of artificial intelligence
Deep learning enables machine learning to implement a wide range of applications and expand the field of artificial intelligence. Deep learning has ruthlessly fulfilled various tasks, making it seem that all machine auxiliary functions are possible. Driverless cars, preventive health care, and even better movie recommendations are all in sight or nearing.